Last week, the conference “Random walks on groups” took place at IHP as part of the activities of a trimester on random walks and asymptotic geometry of groups (organized by Indira Chatterji, Anna Erschler, Vadim Kaimanovich, and Laurent Saloff-Coste) from January to March 2014.
Given the very interesting program of this conference, it was not surprising that Amphithéâtre Hermite (where the talks were delivered) was always full.
Today, we will discuss one of the talks of this conference, namely, the talk “On the continuity of Lyapunov spectrum for random products” of Alex Eskin about his joint work (in preparation) with Artur Avila and Marcelo Viana.
As usual, all mistakes/errors in this post are entirely my responsibility.
Remark 1 A video of a talk of Artur Avila on the same subject can be found here.
Update [February 11, 2014]: Last Friday, I was lucky enough to get some extra explanations concerning “costs of couplings” directly from Alex. At the end of this post (see the “Epilogue”), I will try to briefly summarize what I could understand from this conversation.
1. Introduction
Let 


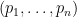



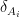
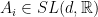
Consider the random walk on 
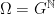
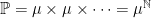



Remark 2 Of course, the intuition here is that the samples
,
whenever we perform a random choice of
with respect to
(or, equivalently, random choices of
‘s with probability distribution
In this context, the Oseledets multiplicative ergodic theorem says that:
Theorem 1 (Oseledets) For
, one has
where
is a symmetric matrix with eigenvalues
. (Here,
is the transpose matrix of
, and
denotes the non-negative symmetric matrix such that
.)
![\displaystyle [A(n,w)^T A(n,w)]^{\frac{1}{2n}}\rightarrow\Lambda](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5BA%28n%2Cw%29%5ET+A%28n%2Cw%29%5D%5E%7B%5Cfrac%7B1%7D%7B2n%7D%7D%5Crightarrow%5CLambda&bg=ffffff&fg=000000&s=0&c=20201002)
The numbers 
Geometrically, Oseledets theorem says that the random walk 
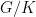
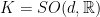
Remark 3 The top Lyapunov exponent
can be recovered by the formula
for
, and the remaining Lyapunov exponents can be recovered by the following standard trick/observation: the top Lyapunov exponent of the action of
-th exterior power
is
. For this reason, it is often (but not always!) the case that the results about the top Lyapunov exponent also provide information about all Lyapunov exponents.

Historically, the first results about the Lyapunov exponents of random products 
Definition 2 We say that
of subspaces of
such that
for all
.

Definition 3 We say that
such that
has distinct eigenvalues. (Here,
is the Zariski closure of the group generated by
.)
Remark 4 If
is Zariski dense in
Theorem 4 (Guivarch-Raugi, Goldstein-Margulis)
- 1) If
(i.e., the top Lyapunov exponent is simple/has multiplicity
- 2) If
.
2. Statement of the main result
In their work, Avila, Eskin and Viana consider how the Lyapunov exponents change when the probability distribution varies. Among the results that they will prove in their forthcoming article is:
Theorem 5 (Avila-Eskin-Viana) Suppose
whose support
varies. Then, for each
, the Lyapunov exponent
is a continuous function of
.

Remark 5 This statement looks innocent, but it is known that Lyapunov exponents do not vary continuously (only upper semi-continuously) “in general”. See, e.g., this article of Bochi (and the references therein) for more details.
3. Previous works and related results
The theorem of Avila-Eskin-Viana generalizes to any dimension 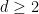

Theorem 6 (Bocker-Neto-Viana) For a fixed probability vector
depend continuously on
.
On the other hand, if one decides to fix the support
Theorem 7 (Peres) Let us fix the support
. Then, the simple Lyapunov exponents of
are locally real-analytic function of
. More precisely, given
and a probability vector
such that the
th Lyapunov exponent is simple (i.e., multiplicity
.
The formula 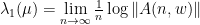
A slightly more useful formula was found by Furstenberg:
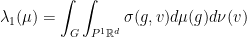
where 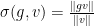


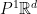
Of course, the cocycle 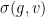


For example, if one feeds the following remark
Remark 6 If
to Furstenberg’s formula, then one can deduce:
Proposition 8 Suppose
(in the weak-* topology),
is proximal and strongly irreducible. Then,
.
Proof: Denote by 

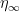



Remark 7 Le Page showed that the conclusion of the previous proposition can be improved from continuity to real-analyticity. However, in general (without strong irreducibility and proximality of
4. Some ideas of the proof of Avila-Eskin-Viana theorem
Let us simplify the exposition by considering the following toy case: we are given two sequences of matrices
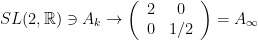
and

and we want to show that the top Lyapunov exponents of the probabilities

converge to

The projective actions of the matrices 

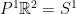
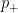



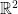


with 
Therefore, if we denote by

and our goal is to show that 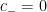
In this direction, the notion of Margulis function comes at hand. Given a probability measure 
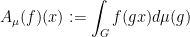
be the Markov operator associated to 
- 1)
- 2)
on a “negligible set”
- 3) there are constants
and
such that
, i.e., when
is large at a point (a step of a
), the value of

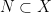
Coming back to toy case, it is possible to show that for 

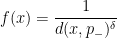
is a Margulis function for
This type of information is useful to show simplicity of the Lyapunov exponents of 
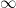
Here, one can try to overcome the technical obstacle of the moving south poles of 
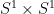

for 
Unfortunately, we made no progress at all with the idea in the previous paragraph: indeed, the technology of Margulis functions requires globally defined functions and so far we were able only to exhibit locally defined functions (in a neighborhood of
At this point, the basic idea of Avila-Eskin-Viana is the introduction of measure-theoretical analogs of Margulis functions. In other terms, they want to replace “functions” by “measures” to get objects that are slightly more flexible but still capable of doing the same job than Margulis functions.
The measure-theoretical analog of Margulis functions are called couplings with finite costs. Concretely, we say that a probability measure 

where 
In this setting, we can see that the task of showing 

for all 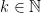

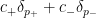
At this point, the time of Alex Eskin was essentially out and he concluded by saying that the main point is that finding couplings with finite costs is easier than building globally defined Margulis functions, and the desired couplings
5. Epilogue
Let us try to give more explanations to the discussion in the previous 6 paragraphs above (following my conversation with Alex Eskin [or what I can remember of it…]).
We start by selecting the small neighborhood 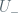



to
Then, we restrict our measures 
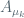


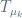
In these terms, the “local version”

of the “usual candidate to Margulis function” 

with 

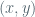
For this reason, Avila-Eskin-Viana replace “functions” by “measures” with the idea that this probabilistic tendency felt by most couples
More concretely, by selecting an appropriate subinterval 

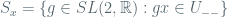
of elements of 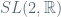






However, this is not quite the end of the history: we need couplings 
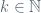



for some universal constants
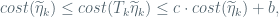
that is,

In other terms, the analog for measures of item 3) in the definition of Margulis functions allows to check that the costs of the sequence optimal cost couplings 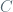

Dear Professor Matheus
Hi. First of all, i am really thankful because of your nice blog. I have learnt many things from it. I have a question. As far as i know, Avila,Eskin and Viana have annocned which we have proved continuity Lyapunov exponents for arabitary dimension but there is no paper for it. I have been looking for it for some month, even i asked many people, nobody knows about it. Let me know, Do you know, they actully proved it? I know, they gave some talks about their result but after 4, they have not written it. Do you have a preliminary version of their article?
Best regards
Reza
By: Reza on December 21, 2018
at 10:29 am
Dear Reza,
As far as I know, you’re absolutely right: the preprint of Avila-Eskin-Viana is not publicly available yet.
Nevertheless, Viana wrote recently a survey (http://w3.impa.br/~viana/out/CS.pdf) containing an exposition of some ideas leading to particular cases of the results claimed by Avila-Eskin-Viana.
Finally, while I don’t have a copy of their preprint, I think you can try to ask one of the authors (say Viana) for a preliminary version of their article.
Best,
Matheus
By: matheuscmss on December 22, 2018
at 10:40 am